1 Abstract¶
Authentication tokens will be used by the science platform as web authentication credentials, for API and service calls from outside the Science Platform, and for internal service-to-service and notebook-to-service calls. This document lays out the technical design of the token management component, satisfying the requirements given in SQR-044.
Warning
This tech note is an obsolete design document for the token management component of the Science Platform identity management system. The design presented here has been heavily revised and is no longer current. See the Gafaelfawr documentation for the current token API, and DMTN-224 and SQR-069 for more up-to-date implementation details including storage formats.
Still of possible interest in this document are the Kafka design, the specification for the housekeeping process, the API for authentication history, and the details of the desired token UI. These have not yet been implemented, and the design in this tech note is still the most recent. If they are implemented, newer designs will be incorporated into DMTN-234 and DMTN-224.
This is part of a tech note series on identity management for the Rubin Science Platform. The primary documents are DMTN-234, which describes the high-level design; DMTN-224, which describes the implementation; and SQR-069, which provides a history and analysis of the decisions underlying the design and implementation. See the references section of DMTN-224 for a complete list of related documents.
2 Scope¶
This design covers the token component in isolation. The user management, group management, and quota components will be designed separately. That may result in some changes to this design as the rest of the system is built. If so, this document will be updated accordingly.
In addition to the requirements in SQR-044, see SQR-039 for a discussion of authentication and authorization for the Science Platform.
This specification will be implemented in Gafaelfawr, the authentication and authorization service for the Rubin Science Platform.
This specification includes tracking of members of a token admin group. This is a temporary stopgap until the group component described in SQR-044 is available. It is therefore the simplest mechanism that can work, rather than implementing something more complete and functional.
2.1 User metadata¶
Eventually, metadata about the user as opposed to their session or authentication token (full name, group memberships, UID, etc.) will be stored in a separate user management system that will provide an API to retrieve that information given an authentication token. However, that component of the overall identity management system has not yet been built. Instead, authorization is currently reliant on user metadata communicated via OAuth 2.0 or OpenID Connect and encoded in the resulting identity token.
Therefore, as an interim measure, user metadata is associated with each authentication token and stored with it. The token service provides an API to retrieve that metadata. The storage elements and APIs to support this are flagged below and should be considered temporary.
User-created tokens will, temporarily, inherit the user metadata (including group membership) from the session token used to create that user token. This means group membership will be encoded in the session data for that token and the token will have to be reissued to change that information, contrary to the design in SQR-044 and SQR-039. This will be fixed once the user metadata component is available as a separate service.
3 Overview¶
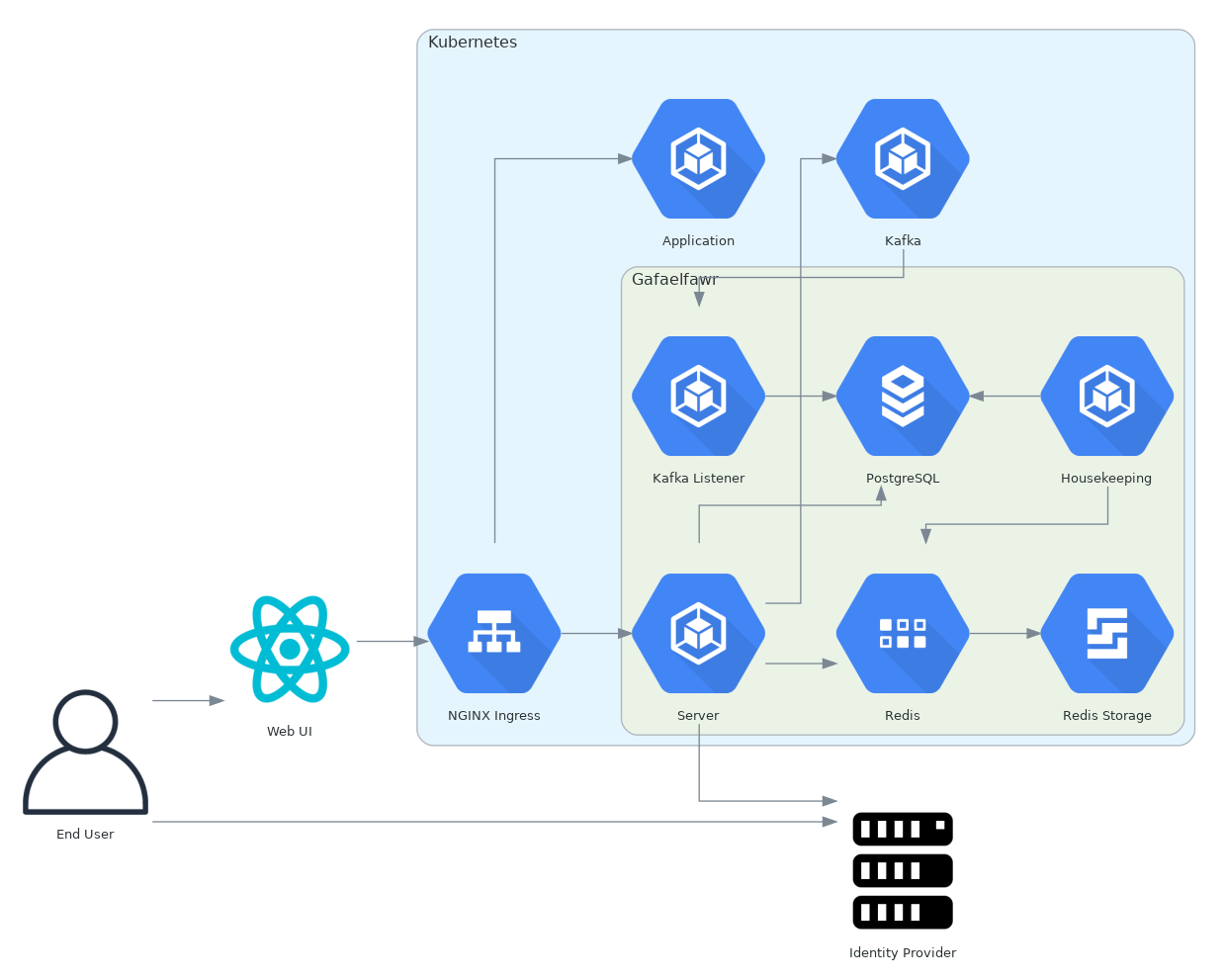
Figure 1 Token management architecture¶
3.1 User flow¶
Here are some typical user token authentication flows.
User authenticates using an identity provider and obtains a session token. (Initial session token issuance is outside the scope of this design; see Gafaelfawr for more information.)
User accesses an application. The token is retrieved from the session and checked against the required scope for that application via the
auth_requesthandler.User spawns a notebook. The notebook spawner requests a notebook token via the
auth_requesthandler. A new notebook token is created as a subtoken of the session token and made available to the notebook spawner via a request header. The notebook spawner arranges to make that token available to the spawned notebook server.User makes a request via a web interface that requires talking to another backend service. The web service requests an internal token via the
auth_requesthandler with appropriate scope. The web service receives that token and uses it to make requests on behalf of the user. This may repeat recursively if that backend service needs to make requests to another service.User makes a request via an API from their notebook server. The notebook token is used for this request and checked by the
auth_requesthandler.User makes a request via an API from the notebook server that requires making subrequests on the user’s behalf. This follows the same pattern as the equivalent case with a web UI: the backend service requests a subtoken and uses it.
User goes to the token management page and creates a user token. This is created as a new token, not as a subtoken of the session token, but (for now) inherits the user metadata from the session token. User stores that token locally on their laptop and uses it to make a request to an API service. The token is checked by the
auth_requesthandler.User makes an API call with their user token that requires making subrequests to other services. This proceeds as with web UIs and notebook API calls.
3.2 Service flow¶
Here are some typical authentication flows for service tokens, used for requests by a service that have no prompting request from a user.
Administrator authenticates with a bootstrap admin token and creates a service token with the
admin:tokenscope. That service token is then stored as a secret for an application that needs administrative capabilities.Application uses a service token with
admin:tokenscope to create a newusertoken for an arbitrary user. The application can then use that token to authenticate as a user to other services. This flow might be used by a load-testing or monitoring application, for example.Administrator uses the bootstrap admin took to create a service token with some normal, non-admin scope. Administrator them stores that service token as a secret for another application. The application can then use that token to make API calls to other serivces that require that scope. Child notebook and internal tokens are created as subtokens of that token as required.
4 Storage¶
Storage for authentication tokens is divided into two backend stores: a SQL database and Redis. Redis is used for the token itself, including the authentication secret. It contains enough information to verify the authentication of a request and return the user’s identity. The SQL database stores metadata about a user’s tokens, including the list of currently valid tokens, their relationships to each other, and a history of where they have been used from.
Use of two separate storage systems is unfortunate extra complexity, but Redis is poorly suited to store relational data about tokens or long-term history, while PostgreSQL is poorly suited for quickly handling a high volume of checks for token validity. Redis also serves, in this interim design, as the store of user metadata.
Kafka is used to record authentication events and off-load updates of the relevant database tables to a separate process.
4.1 Token format¶
A token is of the form gt-<key>.<secret>.
The gt- part is a fixed prefix to make it easy to identify tokens.
The <key> is the Redis key under which data about the token is stored.
The <secret> is an opaque value used to prove that the holder of the token is allowed to use it.
Wherever the token is named, such as in UIs, only the <key> component is given, omitting the secret.
When the token is presented for authentication, the secret provided is checked against the stored secret for that key.
Checking the secret prevents someone who can list the keys in the Redis session store from using those keys as session handles.
4.2 Usernames¶
Usernames, from whatever source, must consist only of lowercase letters, period (.), dash (-), and underscore (_).
Usernames from GitHub, which is case-insensitive, will be mapped to lowercase during authentication and will appear in the token system only in lowercase form.
The one exception is the bootstrap token (see boostrapping), which does not exist as a regular token in any of the data stores but which can appear as an actor in change logs.
That token has a username of <bootstrap>, which would otherwise be invalid.
4.3 Scopes¶
Each token is associated with zero or more scopes. These scopes are used to control access to services. Subtokens are normally created with the same scope as their parent token, and user tokens are normally craeted with the same scope as the token used to authenticate to the token creation API. However, the scope of such tokens can be limited at creation time. The mechanism to do so is described under API and the auth request handler.
Scopes beginning with admin: are reserved for the authentication and authorization component of the Science Platform.
The scope admin::token is used to control access to the token admin API.
4.4 Database¶
All schemas shown below are for PostgreSQL.
Each user has one or more authentication tokens. Those tokens may be of the following types:
session: A web session
user: User-generated token for API access
notebook: Automatically generated token for notebook use
internal: Internal token used for service-to-service authentication
In addition, services may have tokens unconnected from any user. These tokens have the following type:
service: Long-lived token used for service-to-service authentication
An index of current extant tokens is stored via the following schema:
CREATE TYPE token_type_enum AS ENUM (
'session',
'user',
'notebook',
'internal',
'service'
);
CREATE TABLE token (
PRIMARY KEY (token),
token VARCHAR(64) NOT NULL,
username VARCHAR(64) NOT NULL,
token_type token_type_enum NOT NULL,
token_name VARCHAR(64),
scopes VARCHAR(256) NOT NULL,
service VARCHAR(64),
created TIMESTAMP NOT NULL,
last_used TIMESTAMP,
expires TIMESTAMP,
UNIQUE(username, token_name)
);
CREATE INDEX token_by_username ON token (username, token_type, service);
The scopes column is a sorted, comma-separated list of scopes.
If a token has no scopes, the value will be an empty string.
This representation makes it easier to find an existing subtoken with a desired scope than a normalized table.
The service column is only used by internal tokens.
It stores an identifier for the service to which the token was issued and which is acting on behalf of a user.
(Tokens of type service put the name of the service in the username field.)
Internal tokens are derived from other tokens. That relationship is captured by the following schema:
CREATE TABLE subtoken (
PRIMARY KEY (child),
child VARCHAR(64) NOT NULL REFERENCES token ON DELETE CASCADE
parent VARCHAR(64) REFERENCES token ON DELETE SET NULL,
);
CREATE INDEX subtoken_by_parent ON subtoken (parent);
If the parent token is revoked but the child token still exists, the row in this table remains with a NULL parent to indicate that the token is an orphaned child, which may warrant special treatment.
Token usage information is stored in a history table. This will not hold every usage, since that data could be overwhelming for web sessions and other instances of high-frequency calls. However, it will attempt to capture the most recent uses from a given IP address.
It doubles as the web session history table, since web sessions are another type of token.
CREATE TABLE token_auth_history (
PRIMARY KEY (id),
id SERIAL NOT NULL,
token VARCHAR(64) NOT NULL,
username VARCHAR(64) NOT NULL,
token_type token_type_enum NOT NULL,
token_name VARCHAR(64),
parent VARCHAR(64),
scopes VARCHAR(256) NOT NULL,
service VARCHAR(64),
ip_address INET,
event_time TIMESTAMP NOT NULL
);
CREATE INDEX token_auth_history_by_time (event_time, id);
CREATE INDEX token_auth_history_by_token (token, event_time, id);
CREATE INDEX token_auth_history_by_username (username, event_time, id);
This table stores data even for tokens that have been deleted, so it duplicates some information from the token table rather than adding a foreign key.
The service column has the same meaning as in the token table.
The scopes column holds a comma-separated list of scopes.
Authentications by the bootstrap token are logged with a username of <bootstrap>.
Changes to tokens are stored in a separate history table.
CREATE TYPE token_action_enum AS ENUM ('create', 'revoke', 'expire', 'edit');
CREATE TABLE token_change_history (
PRIMARY KEY (id),
id SERIAL NOT NULL,
token VARCHAR(64) NOT NULL,
username VARCHAR(64) NOT NULL,
token_type token_type_enum NOT NULL,
token_name VARCHAR(64),
parent VARCHAR(64),
scopes VARCHAR(256) NOT NULL,
service VARCHAR(64),
expires TIMESTAMP,
actor VARCHAR(64) NOT NULL,
action token_action_enum NOT NULL,
old_token_name VARCHAR(64),
old_scopes VARCHAR(256),
old_expires TIMESTAMP,
ip_address INET,
event_time TIMESTAMP NOT NULL
)
CREATE INDEX token_change_history_by_time (event_time, id);
CREATE INDEX token_change_history_by_token (token, event_time, id);
CREATE INDEX token_change_history_by_username (username, event_time, id);
The actor column contains the username of the token used to authenticate the recorded action.
If the action was authenticated by the bootstrap token, it will be set to <bootstrap>.
The token_name, scopes, and expires fields hold the values for that token at the completion of the recorded action.
In other words, if the action is edit, they hold the values after the completion of the edit.
The columns old_token_name, old_scopes, and old_expires hold the previous values or NULL if that value wasn’t changed.
They are always NULL for an action other than edit.
Note that old_expires may be NULL and still indicate a change in expires from a previous value of NULL.
Compare old_expires to expires to see if the field was changed.
User metadata is not recorded in the token_change_history table, even though this would be desirable for debugging some issues, because the longer-term goal is to remove all user metadata from the token component of the system.
Finally, token admins are stored in a table:
CREATE TABLE admin (
PRIMARY KEY (username),
username VARCHAR(64) NOT NULL
);
and changes to that table are stored in a history table:
CREATE TYPE admin_action_enum AS ENUM ('add', 'remove');
CREATE TABLE admin_history (
PRIMARY KEY (id),
id SERIAL NOT NULL,
username VARCHAR(64) NOT NULL,
action admin_action_enum NOT NULL,
actor VARCHAR(64) NOT NULL,
ip_address INET NOT NULL,
event_time TIMESTAMP NOT NULL
);
CREATE INDEX admin_history_by_time ON admin_history (event_time, id);
4.5 Redis¶
Redis stores a key for each token except for the bootstrap token.
The Redis key is token:<key> where <key> is the key portion of the token, corresponding to the primary key of the token table.
The value is an encrypted JSON document with the following keys:
secret: The corresponding secret for this token
username: The user whose authentication is represented by this token
type: The type of the token (same as the
token_typecolumn)service: The service to which the token was issued (only present for internal tokens)
scope: An array of scope values
created: When the token was created (in seconds since epoch)
expires: When the token expires (in seconds since epoch)
In addition, the following keys store user metadata taken from the OpenID Connect or OAuth 2.0 id token.
These fields are temporary and will be dropped once the user management component is complete.
All of these fields are optional; tokens of type service may not have any of them.
However, some services may reject authentications that don’t have an associated uid value.
name: The user’s preferred full name
email: The user’s email address
uid: The user’s unique numeric UID
groups: The user’s group membership as a list of dicts with two keys, name and id (the unique numeric GID of the group)
This Redis key will be set to expire when the token expires.
This JSON document is encrypted with Fernet using a key that is private to the authentication system. This encryption prevents an attacker with access only to the Redis store, but not to the running authentication system or its secrets, from using the Redis keys to reconstruct working tokens.
4.6 Kafka¶
Putting the latency of a database transaction in the path of each authentication check could cause scaling issues and would defeat the point of storing token information in Redis.
Therefore, rather than update the token and token_auth_history tables on the fly, authentication events are logged to Kafka.
A separate Kafka listener then reads the stream of authentication events and records them in token_auth_history and token.last_used, possibly batching updates to avoid unnecessary database traffic at the cost of losing some granularity in authentication events.
The following Avro schema is used for authentication events:
{
"type": "record",
"name": "auth",
"namespace": "gafaelfawr",
"doc": "Token authentication event",
"fields": [
{
"name": "token",
"type": "string",
"doc": "Key of the token"
},
{
"name": "username",
"type": "string",
"doc": "Username of the user to whom the token was issued"
},
{
"name": "type",
"type": "enum",
"symbols": ["session", "user", "notebook", "internal", "service"],
"doc": "Type of the token"
},
{
"name": "service",
"type": "string",
"default": "",
"doc": "Service to which an internal token was issued"
},
{
"name": "scopes",
"type": "array",
"items": "string",
"default": [],
"doc": "Scopes of the token"
},
{
"name": "ip_address",
"type": "string",
"default": "",
"doc": "Client IP address of authentication event"
},
{
"name": "timestamp",
"type": "long",
"logicalType": "timestamp-millis",
"doc": "Time of event"
}
]
}
Other information about the token not present in Redis but stored in the token_auth_history table, such as its current user-given name and the parent of an internal token, will be looked up in the database when the event is stored.
Kafka is not used for token changes.
Since those already require database modifications, the changes to the token_change_history table are written in the same transaction as the changes to the token.
4.7 Housekeeping¶
To handle token expiration, a job must run periodically that looks for tokens that have expired. For each token found:
Find all child tokens via the
subtokentable. All of those tokens should also be expired since they inherit the expiration of the parent token. (If not, this is a bug that should be reported.) Recursively process the expiration of those tokens first by following this list of actions, and then return to the parent token.Delete the token from
token(which will cause a cascading delete fromsubtoken).Add an entry to
token_change_historywith the metadata values of the token and anactionofexpire.Delete the token from Redis if it exists (it shouldn’t due to the expiration set on the Redis entry).
Housekeeping will also periodically delete all rows in the history tables older than a configurable cutoff period to keep those tables from growing without bound.
Finally, housekeeping will perform periodic consistency checks looking for tokens in Redis but not in the token table or vice versa, orphaned child tokens (entries in subtoken with a NULL for parent), circular token relationships, unknown services, unknown scopes, or scope columns that aren’t in sorted order or separated by commas.
Inconsistencies such as these will be flagged for an administrator.
4.8 Bootstrapping¶
A command-line utility will bootstrap a new installation of the token management system by creating the necessary database schema.
To bootstrap administrative access, this step will take the username of the first administrator as an argument and initialize the admin table with that one member.
That administrator can then use the API or web interface to add additional administrators.
The configuration of the token management system may also include a bootstrap token.
This token will have unlimited access to the API routes /auth/api/v1/admins and /auth/api/v1/tokens and thus can configure the administrators and create service and user tokens with any scope and any identity.
4.9 IP addresses¶
This storage model stores IP addresses for each action in a history table. IP addresses are personally identifiable information and may be somewhat sensitive, but are also extremely useful in debugging problems and identifying suspicious behavior.
This proposal currently does not redact IP addresses, choosing their utility for operational and security purposes over minimizing the data stored. However, this is not a final policy, just an initial design. This will be revisited later.
5 API¶
This design follows the recommendations in Best Practices for Designing a Pragmatic RESTful API. This means, among other implications:
Identifiers are used instead of URLs
The API does not follow HATEOAS principles
The API does not attempt to be self-documenting (see the OpenAPI-generated documentation instead)
Successful JSON return values are not wrapped in metadata
Linkheaders are used for pagination
See that blog post for more reasoning and justification. See References for more research links.
All URLs for the REST API for token manipulation start with /auth/api/v1.
The API will be implemented using FastAPI.
This is a sketch of the critical pieces of the API rather than a complete specification. The full OpenAPI specification of the token API will be maintained as part of the implementation and will replace the routes sections of this document.
The API is divided into two parts: routes that may be used by an individual user to manage and view their own tokens, and routes that may only be used by an administrator.
Administrators are defined as users with authentication tokens that have the admin:token scope.
The first routes can also be used by an administrator and, unlike an individual user, an administrator can specify a username other than their own.
There is some minor duplication in routes (/auth/api/v1/tokens versus /auth/api/v1/users/{username}/tokens and similarly for token authentication and change history).
This was done to simplify the security model.
Users may only use the routes under the users collection with their own username.
The routes under /tokens and /history allow searching for any username, creating tokens for any user, and seeing results across all usernames.
They are limited to administrators.
This could have instead been enforced in more granular authorization checks on the more general routes, but this approach seemed simpler and easier to understand.
It also groups all of a user’s data under /users/{username} and is potentially extensible to other APIs later.
5.1 Errors¶
HTTP status codes are used to communicate success or failure. All errors will result in a 4xx or 5xx status code.
All 4xx HTTP errors for which a body is reasonable return a JSON error body. To minimize the amount of code required on top of FastAPI, these errors use the same conventions as the internally-generated FastAPI errors, namely:
{
"detail": [
{
"loc": [
"query",
"needy"
],
"msg": "field required",
"type": "value_error.missing"
}
]
}
In other words, errors will be a JSON object with a details key, which contains a list of errors.
Each error will have at least msg and type keys.
msg will provide a human-readable error message.
type will provide a unique identifier for the error.
5.2 Pagination¶
Users are expected to have a sufficiently small number of tokens to not require pagination. The admin query for all tokens in the system may be longer, but in the first implementation these also won’t be paginated. We will add pagination later if it becomes necessary.
However, queries for history will require pagination.
To avoid the known problems with offset/limit pagination, such as missed entries when moving between pages, pagination for all APIs that require it will be done via cursors. For the history tables, there is a unique ID for each row and a timestamp. The unique ID will normally increase with the timestamp, but may not (due to out-of-order ingestion). Entries are always returned sorted by timestamp.
Therefore, we can use keyset pagination (the third option in Five ways to paginate in Postgres) with a slight modification. When returning the first page, the results will be sorted by timestamp and then unique ID and a cursor for the next page will be included. That cursor will be the unique ID for the last record, an underscore, and the timestamp for that record (in seconds since epoch). If the client requests the next page, the server will then request entries older than or equal to that timestamp, sorted by timestamp and then by unique ID, and excluding entries with a matching timestamp and unique IDs smaller than or equal to the one in the cursor. This will return the next batch of results without a danger of missing any.
The cursor may also begin with the letter p for links to the previous page.
In this case, the relations in the SQL query are reversed (newer than or equal to the timestamp, unique IDs greater than or equal to the one in the cursor).
The pagination links use the Link (see RFC-8288) header to move around in the results, and an X-Total-Count custom header with the total number of results.
Example headers for a paginated result:
Link: <https://example.org/auth/api/v1/history/token-auth?limit=100&cursor=345_1601415205>; rel="next"
X-Total-Count: 547
Links of type next, prev, first, and last will be included.
If the tokens route eventually needs pagination, we can use a similar approach of a cursor based on the sort keys for the result set.
5.3 User routes¶
For all routes listed below with a username path parameter, only tokens with admin:token scope may specify a username other than their own.
POST /auth/api/v1/loginUsed only by the web frontend. No data is sent with the request. The reply includes the CSRF value to use for all subsequent requests. See API security for more information. It also returns the authenticated username, current scopes, and the configured scopes with their descriptions to assist in forming subsequent queries and to provide information to the UI. Example:
{ "csrf": "d56de7d8c6d90cc4a279666156c5923f", "username": "alice" "scopes": ["read:all"], "config": { "scopes": [ { "name": "admin", "description": "Full admin access" }, { "name": "read:all", "description": "Read all data" } ] } }
GET /auth/api/v1/users/{username}/tokensReturn all tokens for the given user. Example:
[ { "token": "DpBVCadJpTC-uB7NH2TYiQ", "token_type": "session", "created": 1600723604, "last_used": 1600723604, "expires": 1600810004, }, { "token": "e4uA07XmH5nwkfkPQ1RQFQ", "username": "alice", "token_type": "notebook", "created": 1600723606, "expires": 1600810004, "parent": "DpBVCadJpTC-uB7NH2TYiQ" }, { "token": "N7PClcZ9zzF5xV-KR7vH3w", "username": "alice", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read", "user:write"], "created": 1600723681, "last_used": 1600723682 } ]
POST /auth/api/v1/users/{username}/tokensCreate a new token for the given user. Only user tokens may be created this way. Tokens of other types are created through non-API flows described later. The token name, scopes, and desired expiration are provided as parameters. Example request:
{ "token_name": "personal laptop", "scopes": ["user:read", "user:write"], "expires": 1600727294 }
expiresmay benullor omitted to set the token to never expire.scopesmay be omitted to include no scopes in the generated token. Otherwise, the provided scopes must be a subset of the scopes of the token used to authenticate this API call.The newly-created token is returned as follows:
{ "token": "gt-qVGZIh65TAJlNprOaMDhwg.WlUA5zyAY16dDRvDYxnwhg" }
GET /auth/api/v1/users/{username}/tokens/{key}Return the information for a specific token. Example:
{ "token": "N7PClcZ9zzF5xV-KR7vH3w", "username": "alice", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read", "user:write"], "created": 1600723681, "expires": 1600727294, "last_used": 1600723682 }
PATCH /auth/api/v1/users/{username}/tokens/{key}Update data for a token. Only the
token_name,scopes, andexpiresproperties can be changed. Example request:{ "token_name": "new token name", "scopes": ["user:read"], "expires": null }
Properties that should not be changed may be omitted. The requested scopes must be a subset of the scopes of the token used to authenticate this API call.
expiresmay benullto set the token to never expire.DELETE /auth/api/v1/users/{username}/tokens/{key}Revoke a token. This also recursively revokes all child tokens of that token.
GET /auth/api/v1/users/{username}/tokens/{key}/change-historyReturn the change history information for a single token. Example:
[ { "token": "N7PClcZ9zzF5xV-KR7vH3w", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read"], "actor": "charlotte", "action": "create", "ip_address": "192.88.99.2", "timestamp": 1600725748 }, { "token": "N7PClcZ9zzF5xV-KR7vH3w", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read", "user:write"], "actor": "charlotte", "action": "edit", "old_scopes": ["user:read"], "ip_address": "2001:0db8:85a3:0000:0000:8a2e:0370:7334", "timestamp": 1600725767 } ]
GET /auth/api/v1/users/{username}/token-auth-historyGet a history of authentication events for the given user. The range of events can be controlled by pagination and search parameters included in the URL:
cursor: Used for pagination.limit: Maximum number of events to returnsince: Return only events after this timestampuntil: Return only events until this timestampkey: Limit to authentications involving the given key (including child tokens of that key)token_type: Limit to authentications with the given token typeip_address: Limit to events from the given IP address or CIDR block
Pagination is done via an optional
cursorparameter.Example:
[ { "token": "DpBVCadJpTC-uB7NH2TYiQ", "token_type": "session", "ip_address": "192.88.99.2", "timestamp": 1600725470 }, { "token": "e4uA07XmH5nwkfkPQ1RQFQ", "parent": "DpBVCadJpTC-uB7NH2TYiQ", "token_type": "notebook", "timestamp": 1600725676 }, { "token": "N7PClcZ9zzF5xV-KR7vH3w", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read", "user:write"], "ip_address": "2001:0db8:85a3:0000:0000:8a2e:0370:7334", "timestamp": 1600725767 } ]
Available history will be limited by the granularity of history event storage. For example, multiple web accesses in a short period of time may be aggregated into a single authentication event.
GET /auth/api/v1/users/{username}/token-change-historyGet a history of token creation, revocation, and edit events for the given user. Only administrators may specify a username other than their own. The range of events can be controlled by pagination and search parameters included in the URL:
cursor: Used for pagination.limit: Maximum number of events to returnsince: Return only events after this timestampuntil: Return only events until this timestampkey: Limit to events involving the given key (including child tokens of that key)token_type: Limit to events with the given token typeip_address: Limit to events from the given IP address or CIDR block
Pagination is done via an optional
cursorparameter.Example:
[ { "token": "DpBVCadJpTC-uB7NH2TYiQ", "token_type": "session", "actor": "alice", "action": "create", "ip_address": "192.88.99.2", "timestamp": 1600725470 }, { "token": "DpBVCadJpTC-uB7NH2TYiQ", "token_type": "session", "actor": "alice", "action": "revoke", "ip_address": "192.88.99.5", "timestamp": 1600725470 }, { "token": "N7PClcZ9zzF5xV-KR7vH3w", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read", "user:write"], "actor": "charlotte", "action": "edit", "old_scopes": ["user:read"], "ip_address": "2001:0db8:85a3:0000:0000:8a2e:0370:7334", "timestamp": 1600725767 } ]
GET /auth/api/v1/token-infoReturn information about the provided authentication token. (The last used time is nonsensical for this API and is therefore omitted.) This route cannot be used with the bootstrap token. Example:
{ "token": "N7PClcZ9zzF5xV-KR7vH3w", "username": "alice", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read", "user:write"], "created": 1600723681, "last_used": 1600727280, "expires": 1600727294, "parent": "DpBVCadJpTC-uB7NH2TYiQ" }
GET /auth/api/v1/user-infoReturns user metadata for the user authenticated by the provided token. This route cannot be used with the bootstrap token. This is a temporary API until the user management service is available. It returns information from the upstream OAuth 2.0 or OpenID Connect provider that was cached in the token session. Example:
{ "username": "alice", "name": "Alice Example", "email": "alice@example.com", "uid": 24187, "groups": [ { "id": 4173, "name": "example-group" }, { "id": 5671, "name": "other-group" } ] }
All fields other than
usernameare optional.
5.4 Administrator routes¶
The following APIs may only be used by tokens with the admin:token scope.
The /auth/api/v1/admins API is a temporary stopgap until the group system specified in SQR-044 is available.
GET /auth/api/v1/tokensReturn information about all extant tokens. Example:
[ { "token": "DpBVCadJpTC-uB7NH2TYiQ", "username": "alice", "token_type": "session", "created": 1600723604, "last_used": 1600723604, "expires": 1600810004, }, { "token": "e4uA07XmH5nwkfkPQ1RQFQ", "username": "alice", "token_type": "notebook", "created": 1600723606, "expires": 1600810004, "parent": "DpBVCadJpTC-uB7NH2TYiQ" }, { "token": "N7PClcZ9zzF5xV-KR7vH3w", "username": "alice", "token_name": "personal laptop", "token_type": "user", "scopes": ["user:read", "user:write"], "created": 1600723681, "last_used": 1600723682 } ]
POST /auth/api/v1/tokensCreate a new token for the given user. The bootstrap token may be used to authenticate to this route. Only user and service tokens may be created this way. Tokens of other types are created through non-API flows described later. The username, token type, token name (for a user token), scopes, and desired expiration are provided as parameters. The full name, email address, numeric UID, and group membership may also be provided and will populate the user metadata associated with this token. Example request:
{ "username": "mobu", "token_type": "service", "scopes": ["admin:token"], "expires": null }
expiresmay benullor omitted to set the token to never expire.The newly-created token is returned as follows:
{ "token": "gt-qVGZIh65TAJlNprOaMDhwg.WlUA5zyAY16dDRvDYxnwhg" }
GET /auth/api/v1/adminsGet the list of current administrators. The bootstrap token may be used to authenticate to this route. Example:
[ { "username": "charlotte" } ]
POST /auth/api/v1/adminsAdd a new administrator. The bootstrap token may be used to authenticate to this route.
DELETE /auth/api/v1/admins/{username}Remove an administrator. The bootstrap token may be used to authenticate to this route. The last administrator cannot be removed. Note that administrator usernames are not verified, and therefore it is possible to add a bogus username and then remove the last working admin. This is not addressed because this API is a temporary stopgap.
GET /auth/api/v1/history/adminsGet a history of changes to the list of administrators. The range of events can be controlled by pagination and search parameters included in the URL:
cursor: Used for pagination.limit: Maximum number of events to returnsince: Return only events after this timestampuntil: Return only events until this timestamp
Example:
[ { "username": "charlotte", "action": "add", "actor": "alice", "ip_address": "192.88.99.4", "timestamp": 1600812808 } ]
GET /auth/api/v1/history/token-authGet a history of token authentications. The range of events can be controlled by pagination and search parameters included in the URL:
cursor: Used for pagination.limit: Maximum number of events to returnsince: Return only events after this timestampuntil: Return only events until this timestampusername: Limit to events for the given usernamekey: Limit to events involving the given key (including child tokens of that key)token_type: Limit to events with the given token typeip_address: Limit to events from the given IP address or CIDR block
Pagination is done via an optional
cursorparameter.The output is the same as
/auth/api/v1/users/{username}/token-auth-historyexcept that theusernamefield is included in each returned record.GET /auth/api/v1/history/token-changesGet a history of token changes. This API is limited to administrators. The range of events can be controlled by pagination and search parameters included in the URL:
cursor: Used for pagination.limit: Maximum number of events to returnsince: Return only events after this timestampuntil: Return only events until this timestampusername: Limit to events for the given usernameactor: Limit to events with the given actorkey: Limit to events involving the given key (including child tokens of that key)token_type: Limit to events with the given token typeip_address: Limit to events from the given IP address or CIDR block
Pagination is done via an optional
cursorparameter.The output is the same as
/auth/api/v1/users/{username}/token-change-historyexcept that theusernamefield is included in each returned record.
5.5 Security¶
API calls may be authenticated one of two ways: by providing a token in an Authorization header with type bearer, or by sending a session cookie.
The session cookie method will be used by web frontends.
Direct API calls will use the Authorization header.
All API POST, PATCH, or DELETE calls authenticated via session cookie must include an X-CSRF-Token header in the request.
The value of this header is obtained via the /auth/api/v1/login route.
This value will be checked by the server against the CSRF token included in the session referenced by the session cookie.
Direct API calls authenticating with the Authorization header can ignore this requirement.
This API does not support cross-origin requests.
It therefore should respond with an error to OPTIONS requests.
6 Web UI¶
The web interface will be written in React using Gatsby and styled-components. The frontend will use the same API as API clients to retrieve and change data.
6.1 User interface¶
General users will have access to the following pages:
- Token list
Lists all of the unexpired tokens for the current user. The token list is divided into separate sections for web sessions, user-created tokens, and notebook tokens, with internal tokens shown under their parent tokens. The last-used time is shown with each token, rendered as a human-readable delta from the current time (for example, “10 minutes ago” or “1 month ago”) with a more accurate timestamp available via mouse-over or some other interface. From this list the user can revoke any token.
- View a specific token
Shows the details for a single token, including its modification and authentication history. The user can also revoke the token from this page.
- Create new token
Creates a new user token and displays the full token (including the secret) to the user once. The user can select a name, list of scopes (chosen from a selection list), and optional expiration. The optional expiration should offer a standard selection of reasonable lengths of time as well as allow the user to enter their own.
- Modify a token
Allows the user to modify the name, scope, or expiration date of an existing token.
- Token authentication history
Shows a paginated list of token authentication events for the user, divided into web sessions, user-created tokens, notebook tokens, and internal tokens. The user can limit by token type or date, or click on a token to see its details.
- Token modification history
Shows a paginated list of token creation, revocation, and modification events for the user, divided into web sessions, user-created tokens, notebook tokens, and internal tokens. The user can limit by token type or event date, or click on a token to see its details.
6.2 Admin interface¶
Any administrator can impersonate a user and see the same pages that user would see. When this is happening, every page displays a banner indicating that impersonation is being done and identifying the actual user.
Administrators also have access to additional pages:
- Admin list
List all current administrators. An administrator can be deleted from this page if they aren’t the last administrator. A new administrator can be added by username. Currently, usernames are not validated. Eventually, they will be validated against the user management system.
- Admin history
Lists (with pagination) changes to the list of administrators.
- Admin token list
Lists (with pagination) all of the current-valid tokens known to the system. Allows restricting the view by token types and users.
- Admin token creation
Creates a new token for any user, with a type of either
userorservice. This is how new service tokens are created through the UI. It also allows admins to create user tokens to impersonate any user.- Admin token view
Shows the details of any single token, including its authentication history. The token can be revoked from this page.
- Admin token authentication history
Shows a paginated list of all recent token authentication events. Allows restricting by IP address or CIDR block, token types, users, and date range.
- Admin token modification history
Shows a paginated list of all recent token creation, revocation, and modification events. Allows restricting by IP address or CIDR block, token types, users, and date range.
6.3 Security¶
The React web UI will not attempt to authenticate the user internally.
Instead, it will make an authentication request to the backend server using the /auth/api/v1/login route to get a CSRF token.
That and all other API requests will be authenticated via session cookie, which contains a session token.
Details on how that session cookie is created are out of scope for this design. See the Gafaelfawr documentation for more information.
7 auth_request API¶
The primary interaction most Rubin Science Platform components will have with the token management system is via an NGINX auth_request handler.
When configured this way, each incoming request to a protected resource results in a subrequest to Gafaelfawr, which grants or denies the request based on included authentication information.
If the request is granted, additional information is passed to the backend via headers.
The auth_request handler is provided on the /auth route.
The following parameters may be specified as GET parameters to that route.
scope: The scope required to allow access.notebook: If set to a true value, requests a notebook token be passed via a header along with the request.delegate_to: Requests an internal token that will be passed via a header along with the request. The value of this parameter is an identifier for the service that will use this subtoken to make additional requests on behalf of the user.delegate_scope: A comma-separated list of scopes that the subtoken should have. This must be a subset of the scopes the authenticating token has, or theauth_requesthandler will deny access.
The delegate_to and notebook parameters are mutually exclusive.
The auth_request handler may support other parameters unrelated to the token management component.
7.1 Internal tokens¶
When an internal token is requested via the delegate_to parameter, the auth_request handler will find a child token of the current token with the appropriate service and scope values.
If one does not exist, a new child token with appropriate values will be created.
The child token inherits its values (such as the temporarily-stored user metadata) from the parent token, except for its expiration (see below).
The parent token may be of any type, including another internal token, creating chains of delegated tokens.
Child tokens have a maximum lifetime to limit their power. That lifetime is configurable (globally) and will start at two days. We will adjust that configuration if this isn’t long enough for long-running API calls or batch processing. If a parent token’s lifetime is shorter than that maximum lifetime, the child token inherits its expiration from the parent token. Otherwise, the child token’s lifetime is set to the maximum lifetime.
Before creating a new child token for a given delegate_to request, the token system will check whether a child token of the given parent token already exists with appropriate service and scope.
If so, that existing token will be used instead of issuing a new one provided that either its expiration matches that of the parent token or, for parent tokens that do not expire or whose remaining lifetime is longer than half the maximum lifetime, its expiration is not more than half exhausted.
In other words, an internal token created from a non-expiring parent token with the starting two day lifespan will be reused for a day, after which a new one will be created.
To avoid the latency of database queries in the common case of multiple requests with the same token to a service requesting the same service and scope values for an internal token, the auth_request handler may internally cache a mapping of parent token to child tokens for given service and scope values.
As long as the referenced child token is still valid according to Redis, this mapping may be cached for up to the expiration time of the parent token or halfway to the expiration time of the child token, whichever is shorter.
After that point, a new child token for that service and scope pair will be created.
This cache will be stored in memory for each worker and lost if that worker is restarted.
Reconstructing the cache is relatively inexpensive (just a few SQL queries for the first time a worker sees that parent token, service, and scope tuple).
8 Kubernetes secrets¶
In a couple of cases, Gafaelfawr tokens will need to be maintained as Kubernetes secrets.
8.1 Service tokens¶
Normally, protected services will request a delegated token on behalf of the user and make other API calls using that token. However, in some cases services will need to make calls on their own behalf. Examples include administrative services for user provisioning, monitoring systems that need to forge user tokens to test as a user, and internal systems that are easier to deploy as individual microservices that need to authenticate to each other.
To support this use case, the token management system can be configured to maintain a valid service token in a Kubernetes secret. That secret can then be made available to the service that needs it through normal Kubernetes mechanisms.
In the initial implementation, this will be done by configuring the token management system with a list of secrets to manage.
A periodic job (implemented via a Kubernetes CronJob resource) will verify that all of those tokens exist, create them if they are missing, and reissue the token if it somehow became invalid.
Tokens managed in this way will be labeled with:
gafaelfawr.lsst.io/token-type: service
The token will be stored in the token key of the secret.
Any tokens with that label that are not mentioned in the configuration will be deleted (to clean up old, no-longer-needed tokens).
In a later iteration, this configuration will be replaced with a custom resource definition. Services that need a service token will indicate that need by creating a custom Kubernetes resource, and the token management system will create and manage a secret derived from that resource.
8.2 Notebook tokens¶
Notebook tokens are the child tokens delegated to a instance of the Notebook Aspect. They have the same scopes as the user’s authentication token and are used for API calls and other authenticated activities from inside the Kubernetes cluster.
Notebook tokens are child token’s of the user’s browser session token and thus inherit its lifetime. Browser session tokens should expire regularly to minimize the possible damage from cookie leaks and to aid with off-boarding. However, users may wish to keep a notebook session running for an extended period for convenience.
The implication is that the token management system must be able to renew the notebook token associated with a running notebook. This can be done via a Kubernetes secret mounted in the notebook pod, but then the Kubernetes secret must be refreshed. Ideally, this would be done inside JupyterHub, but there does not appear to be a useful hook for noticing when a user returns to a running notebook and updating Kubernetes resources.
Therefore, notebook tokens will be handled as follows:
When a user spawns a notebook, the delegated notebook token JupyterHub receives will be stored in a Kubernetes secret. The token will be in the
tokendata key of the secret. The secret will be labeled with:gafaelfawr.lsst.io/token-type: notebook
The token management system will periodically scan Kubernetes for all secrets with this label. If the token contained in the secret is still a valid notebook token and it has exhausted more than half its lifetime, the token management system will create a new notebook token for the same user and replace the token in the secret with that new token.
Kubernetes will then notice that the secret has been modified and update the mounted token inside the running notebook.
Note that this requires all code running in the notebook that needs to use an authentication token to periodically re-read the token from disk and not rely on a cached token (either in the environment or in code). Otherwise, it won’t see the refreshed tokens.
This artificially extends the lifetime of notebook tokens beyond the lifetime of the token that originally created them. The security effect is to make notebook tokens renewable. In the case of an incident in which a user’s account may have been compromised, it will therefore be important to invalidate all notebook tokens as well as all session tokens. This will immediately invalidate the existing token and also tell the token management system to stop refreshing it.
9 References¶
Here are some useful source documents I relied on for this design.
9.1 Blog posts¶
- Best Practices for Designing a Pragmatic RESTful API
An excellent and opinionated discussion of various areas of RESTful API design that isn’t tied to any specific framework or standard.
- Five ways to paginate in Postgres
A discussion of tradeoffs between pagination techniques in PostgreSQL, including low-level database performance and PostgreSQL-specific features.
- JSON API, OpenAPI and JSON Schema Working in Harmony
Considerations for which standards to use when designing a JSON REST API.
- The Benefits of Using JSON API
An overview of JSON:API with a comparison to GraphQL.
9.2 Standards¶
- FastAPI
The documentation for the FastAPI Python framework.
- JSON:API
The (at the time of this writing) release candidate for the upcoming JSON:API 1.1 specification.
- OpenAPI
The OpenAPI specification for RESTful APIs. Provides a schema and description of an API and supports automatic documentation generation. Used by FastAPI.
- RFC 7807
This document defines a “problem detail” as a way to carry machine-readable details of errors in a HTTP response to avoid the need to define new error response formats for HTTP APIs.
- RFC 8288
This specification defines a model for the relationships between resources on the Web (“links”) and the type of those relationships (“link relation types”). It also defines the serialisation of such links in HTTP headers with the Link header field.